RAG on-prem: architektura, chunking, retrieval i co naprawdę wpływa na jakość
Jak zbudować RAG poza chmurą publiczną: warstwy pipeline'u, najczęstsze błędy retrievalu, granice danych w promptcie i pytania, które zadaje audytor. Notatka techniczna dla architektów i CISO.
Czas czytania: ~7 min
Dla kogo: architekt IT, security architect, CISO, kierownik infrastruktury, który rozważa RAG (retrieval-augmented generation) na własnej infrastrukturze i chce zrozumieć, gdzie ta architektura naprawdę boli, zanim podpisze projekt.
Spis treści
- Po co w ogóle RAG poza chmurą publiczną
- Anatomia pipeline'u RAG (siedem warstw)
- Retrieval: gdzie to się psuje najczęściej
- Co naprawdę trafia do promptu (i dlaczego to problem governance)
- Granice bezpieczeństwa: izolacja, logowanie, kontrola dostępu
- Trzy decyzje architektoniczne, które trudno cofnąć
- Disclosure i biases
- Co tu nie pokrywam
- Powiązane
1. Po co w ogóle RAG poza chmurą publiczną
RAG to wzorzec, w którym model językowy nie odpowiada wyłącznie z własnej wiedzy, lecz dostaje do kontekstu fragmenty dokumentów wyciągnięte z bazy organizacji. Dzięki temu odpowiada na pytania o dane, których nie było w treningu: dokumentację serwisową, umowy, instrukcje BHP, historię zgłoszeń.
Powód, dla którego organizacja stawia RAG na własnej infrastrukturze, jest zwykle jeden: dane, które trafiają do retrievalu, nie mogą opuścić środowiska. Dokumentacja techniczna, dane osobowe pracowników, szczegóły kontraktowe, know-how procesowe. Gdy te treści są indeksowane i wysyłane do publicznego API jako kontekst promptu, organizacja eksportuje je do zewnętrznego procesora, z wszystkimi konsekwencjami, które za tym idą w łańcuchu dostaw.
To nie jest post o tym, czy warto trzymać RAG lokalnie. To zależy od profilu ryzyka i nie ma jednej odpowiedzi. To post o tym, jak taki pipeline wygląda technicznie i gdzie zespoły najczęściej tracą czas albo bezpieczeństwo.
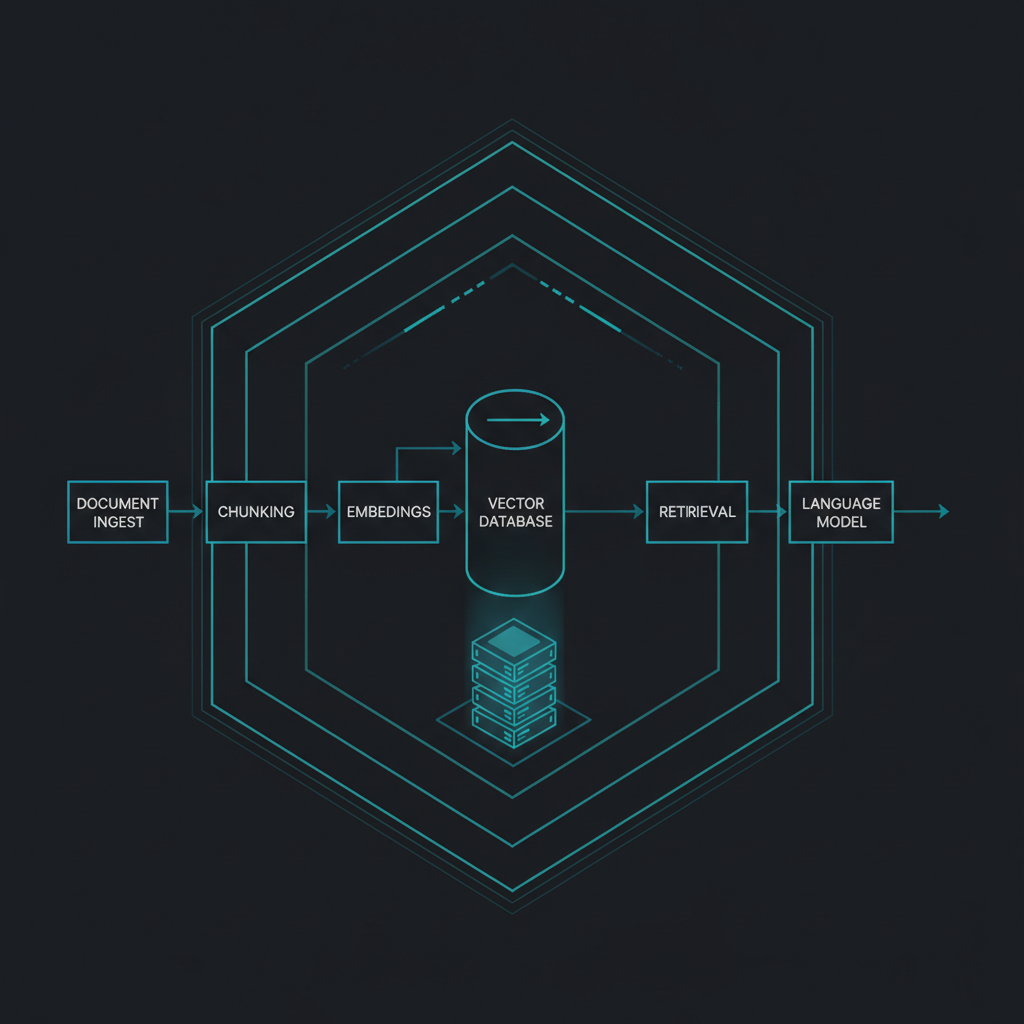
2. Anatomia pipeline'u RAG (siedem warstw)
Działający RAG to nie „baza wektorowa plus model". To łańcuch, w którym każde ogniwo ma własne tryby awarii.
Warstwa 1, ingest i parsing. Dokumenty wchodzą w różnych formatach: PDF (często skany), DOCX, strony intranetu, eksporty z systemów ERP/MES. Parser zamienia je na czysty tekst. Tu ginie najwięcej jakości: tabele rozsypują się w ciąg liczb, nagłówki mieszają się z treścią, skany bez OCR dają pusty wynik.
Warstwa 2, chunking. Tekst jest cięty na fragmenty. Zbyt duże chunki rozmywają trafność; zbyt małe gubią kontekst (zdanie „nie dotyczy modelu X" oderwane od tego, czego nie dotyczy, jest gorsze niż brak zdania).
Warstwa 3, embeddings. Każdy chunk dostaje wektor z modelu embeddującego. W wariancie on-prem ten model też działa lokalnie, a jego jakość dla języka polskiego bywa znacząco gorsza niż dla angielskiego, co rzutuje na cały retrieval.
Warstwa 4, baza wektorowa. Wektory lądują w indeksie (np. pgvector, Qdrant, Milvus). Tu zapadają decyzje o metryce podobieństwa, typie indeksu i filtrowaniu po metadanych.
Warstwa 5, retrieval. Na zapytanie użytkownika system wyszukuje najbardziej zbliżone chunki. To serce wzorca i jednocześnie miejsce, gdzie „działa na demie" najczęściej rozjeżdża się z „działa na produkcji".
Warstwa 6, generacja. Wyszukane fragmenty trafiają do promptu razem z pytaniem, a model językowy formułuje odpowiedź. Tu rozstrzyga się, ile z dostarczonego kontekstu model faktycznie wykorzysta, a ile zignoruje lub przekręci.
Warstwa 7, observability i feedback. Logowanie zapytań, ocena trafności, pętla poprawiania. Najczęściej pomijana warstwa, a bez niej nie da się ani poprawiać systemu, ani udokumentować jego działania przed audytem.
3. Retrieval: gdzie to się psuje najczęściej
Większość rozczarowań RAG-iem to nie wina modelu językowego, tylko retrievalu. Cztery powtarzalne wzorce:
Trafność semantyczna ≠ trafność faktyczna. Wyszukiwanie wektorowe znajduje fragmenty podobne tematycznie, niekoniecznie odpowiadające na pytanie. Pytanie o moment dokręcania konkretnej śruby wyciąga pięć akapitów o śrubach w ogóle, ale niekoniecznie ten jeden z tabelą wartości.
Brak hybrydy. Czyste wyszukiwanie wektorowe gubi zapytania, w których liczy się dokładny token: numer części, kod błędu, sygnatura normy. Wyszukiwanie pełnotekstowe (np. BM25) łapie je natychmiast. Produkcyjne systemy prawie zawsze potrzebują hybrydy wektor + słowo kluczowe, a nie jednego z dwóch.
Brak filtrowania po uprawnieniach na poziomie retrievalu. Jeśli kontrola dostępu jest dopięta dopiero na warstwie aplikacji, a retrieval przeszukuje cały indeks, to model może dostać do kontekstu fragment, którego użytkownik nie powinien zobaczyć, i streścić go w odpowiedzi. Filtr po metadanych uprawnień musi działać w zapytaniu do bazy, nie po nim.
Brak ewaluacji. Bez zestawu testowych pytań z oczekiwanymi źródłami zespół nie wie, czy zmiana chunkingu albo modelu embeddującego poprawiła system, czy go zepsuła. „Wydaje się lepiej" nie jest metryką.
4. Co naprawdę trafia do promptu (i dlaczego to problem governance)
Kluczowa obserwacja, którą łatwo przeoczyć przy projektowaniu: w momencie generacji do promptu modelu trafiają surowe fragmenty dokumentów, często z danymi, których użytkownik zadający pytanie nie ma prawa widzieć w całości, albo które są wrażliwe same w sobie.
To rodzi konkretne pytania, które warto rozstrzygnąć na etapie architektury, nie po incydencie:
- Czy fragmenty trafiające do kontekstu są logowane? Jeśli tak, to gdzie i na jak długo? Log promptów RAG to często zbiór najbardziej wrażliwych danych w całym systemie, bo zawiera wyjęte z kontekstu fragmenty wielu dokumentów naraz.
- Czy maskujemy dane osobowe przed indeksacją, czy ufamy, że nigdy nie wpłyną do promptu? Pierwsze jest kosztowne, drugie jest założeniem, które audytor podważy.
- Kto ma dostęp do bazy wektorowej? Wektory nie są „zaszyfrowane", bo z odpowiednim modelem można z nich odtworzyć znaczną część treści źródłowej. Dostęp do indeksu to z grubsza dostęp do dokumentów.
W kontekście regulacyjnym te pytania nie są teoretyczne. Granica między „dane są u nas" a „dane są w logach systemu, do którego ma dostęp pięć osób bez jasnego uzasadnienia" to dokładnie ten poziom szczegółu, na którym rozstrzyga się ocena ryzyka łańcucha dostaw.
5. Granice bezpieczeństwa: izolacja, logowanie, kontrola dostępu
Trzy obszary, które na on-prem RAG trzeba zaprojektować świadomie, bo nikt nie zrobi tego za organizację:
Segmentacja sieci. Pipeline RAG dotyka źródeł danych (ERP, plikowniki, intranet), bazy wektorowej i serwera modelu. Każde z tych połączeń to potencjalna ścieżka wycieku. Minimalny zestaw reguł: serwer modelu nie inicjuje ruchu wychodzącego, baza wektorowa jest osiągalna tylko z warstwy aplikacji, ingest działa w osobnym segmencie.
Audit logging na poziomie retrievalu. Nie tylko „użytkownik X zadał pytanie", ale „zapytanie X wyciągnęło dokumenty A, B, C i zwróciło odpowiedź Y". Bez tego nie da się odtworzyć, skąd wzięła się błędna albo wrażliwa odpowiedź, a to pierwsze pytanie po incydencie.
Kontrola dostępu propagowana do retrievalu. Powtórzę z sekcji 3, bo to najczęstszy błąd projektowy: uprawnienia muszą filtrować to, co retrieval w ogóle widzi, a nie tylko to, co aplikacja pokaże na końcu.
6. Trzy decyzje architektoniczne, które trudno cofnąć
Model embeddujący. Zmiana modelu embeddującego oznacza przeliczenie całego indeksu od zera. Przy dużych korpusach to godziny do dni pracy GPU i okno, w którym system działa na starych wektorach. Wybór warto przetestować na reprezentatywnym podzbiorze przed indeksacją produkcyjną, ze szczególnym naciskiem na jakość dla polskiego.
Strategia chunkingu. Powiązana z powyższym, bo zmiana sposobu cięcia też wymaga reindeksacji. Warto zainwestować w chunking świadomy struktury dokumentu (sekcje, tabele, nagłówki) zamiast naiwnego cięcia co N znaków.
Granica logowania. Decyzja, co z promptów i kontekstu jest zapisywane, jest trudna do cofnięcia wstecz: dane, które trafiły do logów przez pół roku, już tam są. Lepiej zaprojektować restrykcyjnie i rozluźnić, niż odwrotnie.
Klaster architektury naturalnie spotyka się tu z decyzją build vs buy: które warstwy budujesz i utrzymujesz wewnętrznie, a co domykasz gotowym komponentem. To temat sąsiednich notatek z oceny vendorów, do których wrócę osobno.
// disclosure i biases7. Disclosure i biases
Autor pracuje nad CortexMine, productized on-prem AI platform dla europejskich producentów. Analizy w tym poście mogą być stronnicze w kierunku kategorii productized vs DIY, w szczególności tam, gdzie opisuję koszt utrzymania warstw observability i logowania jako wysoki. Zespół, który ma silne kompetencje MLOps in-house, może ocenić te koszty niżej, niż sugeruje ten tekst. Tam, gdzie to możliwe, starałem się opisywać warstwy neutralnie, niezależnie od tego, kto je dostarcza.
8. Co tu nie pokrywam
- Konkretne benchmarki modeli embeddujących dla polskiego, bo to materiał na osobną notatkę z liczbami, nie na akapit.
- Fine-tuning vs RAG, czyli kiedy warto dotrenować model zamiast budować retrieval; osobny trade-off.
- Architektury agentowe (multi-step retrieval, tool use), bo to warstwa wyżej niż klasyczny RAG.
- Szczegółowe mapowanie na artykuły NIS2. Kontekst regulacyjny sygnalizuję, ale pełne mapowanie żyje w klastrze NIS2.
- Sizing sprzętu pod inference, pokryte osobno w GPU sizing dla Llama 3.1 70B.
9. Powiązane
Buduje CortexMine, on-prem AI platform dla europejskich producentów objętych NIS2. Tam, gdzie ta stronniczość mogłaby zaważyć na wnioskach, oznacza to inline.
GPU sizing dla Llama 3.1 70B inference: liczby z benchmarków
Ile GPU realnie potrzeba, żeby postawić Llamę 3.1 70B u siebie? Konkretne konfiguracje (A100, H100, H200), wpływ kwantyzacji (FP16 → FP8 → INT4), tokens/s, TTFT i koszt per 1M tokenów. Bez marketingu, z liczbami z benchmarków vLLM i TensorRT-LLM.