DIY, productized czy managed: trzy modele on-prem AI i kto je utrzymuje
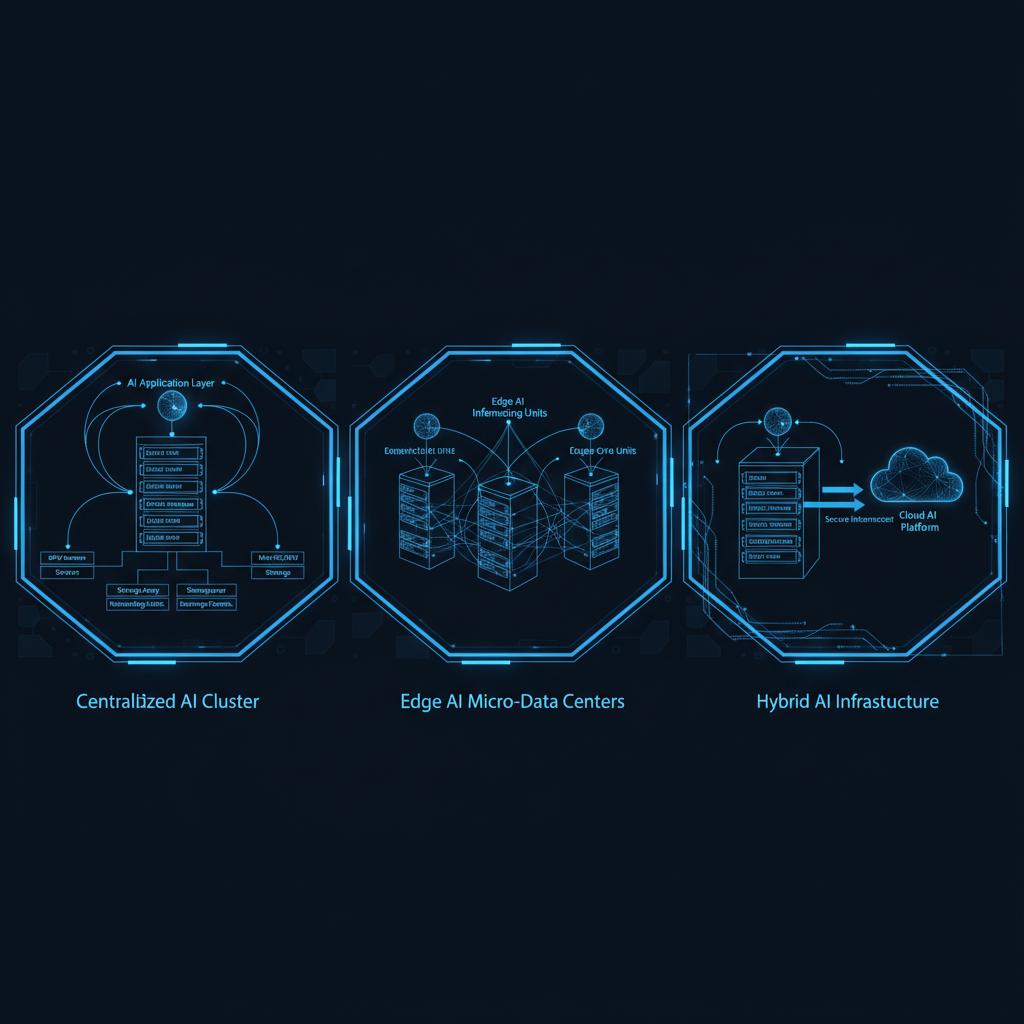
Trzy modele deploymentu on-prem AI: koszty, profil ryzyka, kiedy który
Czas czytania: ok. 11 minut
Kiedy zarząd pyta CISO o "AI on-prem", zwykle ma w głowie jedną rzecz: dane nie wychodzą z organizacji. To dobry instynkt regulacyjny, ale fatalna podstawa do decyzji architektonicznej, bo "on-prem" nie opisuje jednego rozwiązania. Opisuje co najmniej trzy różne modele wdrożenia, które różnią się o rząd wielkości pod względem kosztu, ryzyka i tego, ile własnego zespołu trzeba w to włożyć.
Większość nieudanych projektów on-prem AI, które widziałem lub o których słyszałem, nie poległa na technologii. Poległa na tym, że ktoś podpisał się pod jednym modelem, a budżetował i obsadzał inny. Ten post rozkłada trzy modele na czynniki, żebyście wiedzieli, którą rozmowę naprawdę prowadzicie, zanim wyślecie RFP.
Spis treści
- Co właściwie znaczy "on-prem"
- Model 1: DIY na open-source
- Model 2: Productized appliance
- Model 3: Managed on-prem
- Porównanie: koszt, ryzyko, obciążenie zespołu
- Jak wybrać: cztery pytania
- Disclosure i biases
- Co tu nie pokrywam
Co właściwie znaczy "on-prem"
Ustalmy granice pojęcia, bo to źródło połowy nieporozumień na spotkaniach.
On-prem w sensie ścisłym oznacza, że obciążenie inferencyjne (model, dane, pipeline RAG) działa na infrastrukturze, nad którą organizacja ma kontrolę fizyczną lub kontraktową, a dane nie trafiają do API zewnętrznego dostawcy modelu (OpenAI, Anthropic, Google). To definicja, która ma znaczenie dla NIS2 i RODO, bo dotyczy miejsca przetwarzania i przepływu danych, a nie marki na obudowie serwera.
W tej definicji mieszczą się trzy modele organizacyjne, nie jeden. Różni je nie to, gdzie stoi sprzęt (to zwykle ta sama serwerownia), tylko to, kto buduje, kto utrzymuje i kto bierze odpowiedzialność za to, że całość działa i jest audytowalna. Te trzy pytania definiują koszt i ryzyko bardziej niż jakikolwiek wybór modelu językowego.
Świadomie zostawiam poza zakresem warianty hybrydowe i hostowane u zewnętrznego operatora, gdzie część obciążenia ląduje w chmurze publicznej w trybie izolowanym. To osobny temat, z osobnym profilem ryzyka regulacyjnego, i wrzucanie go tutaj tylko zaciemniłoby obraz.
Model 1: DIY na open-source
Pierwszy model to zbudowanie wszystkiego samodzielnie na komponentach open-source. Bierzecie otwarty model (rodzina Llama, Mixtral, Qwen), serwer inferencyjny (vLLM, TGI, Ollama do prototypu), budujecie własny pipeline RAG, warstwę aplikacyjną, observability, i sami spinacie to w działającą całość na własnym sprzęcie.
Profil kosztów
Koszt licencyjny oprogramowania bywa zerowy, i to jest dokładnie ta liczba, która myli zarządy. Realny koszt siedzi gdzie indziej: w ludziach. Potrzebujecie zespołu, który rozumie serwowanie modeli, kwantyzację, tuning pipeline'u RAG, zarządzanie GPU i utrzymanie tego wszystkiego w czasie. Na rynku, gdzie pensje w kategorii AI/ML są najwyższe w całym polskim IT, to nie jest tania pozycja, a do tego trudno obsadzalna.
Sprzęt kupujecie sami. Dla średniej organizacji, która chce serwować model klasy 70B w rozsądnym tempie dla kilkudziesięciu jednoczesnych użytkowników, mówimy o wydatku na GPU rzędu kilkuset tysięcy złotych wzwyż, zależnie od wybranej konfiguracji i tego, czy budujecie redundancję. To koszt jednorazowy plus amortyzacja, ale dopiero początek rachunku.
Profil ryzyka
Najwyższy z trzech modeli, ale w specyficznym sensie. Ryzyko technologiczne jest opanowywalne, jeśli macie zespół. Prawdziwe ryzyko jest organizacyjne i ma dwie warstwy.
Pierwsza to zależność od kluczowych osób. Jeśli pipeline zbudowały dwie osoby i jedna odejdzie, zostajecie z systemem produkcyjnym, którego nikt do końca nie rozumie. To dokładnie ten rodzaj ryzyka, który audytor NIS2 zacznie kwestionować, bo dotyczy ciągłości i odtwarzalności.
Druga to audytowalność. Złożenie własnego pipeline'u to także obowiązek samodzielnego udokumentowania: skąd biorą się odpowiedzi, jak logowany jest dostęp, jak zarządzane są sekrety, jak wygląda data flow. Komercyjny audytor nie przyjmie "ufajcie nam, działa". DIY znaczy, że ta dokumentacja też jest na waszej głowie.
Kiedy ma sens
DIY ma sens, gdy AI jest dla was kompetencją strategiczną, a nie narzędziem wspierającym. Jeśli macie już zespół data science lub ML platform, który i tak istnieje, i chcecie pełnej kontroli nad każdą warstwą, to model dla was. W praktyce dotyczy to większych organizacji (zwykle 1000+ FTE z dojrzałym IT) albo firm, których produkt sam w sobie jest oparty na AI.
Dla typowego podmiotu kluczowego NIS2 z sektora produkcji, którego core biznesem jest wytwarzanie, a nie budowa platform AI, DIY to zwykle pułapka kosztowa przebrana za oszczędność na licencjach.
Model 2: Productized appliance
Drugi model to gotowy, zproduktyzowany system dostarczany jako spójna całość: oprogramowanie plus warstwa zarządzania, często na predefiniowanej lub dostarczonej konfiguracji sprzętowej, instalowany u was. Kupujecie produkt, nie zestaw komponentów do złożenia. Aktualizacje, pipeline RAG, observability i część dokumentacji audytowej przychodzą z produktem.
Profil kosztów
Wyższy koszt wejścia w oprogramowanie niż przy DIY (płacicie za produkt i za to, że ktoś już rozwiązał problemy integracyjne), ale niższy i bardziej przewidywalny koszt obsady zespołu. Nie potrzebujecie zespołu ML platform, potrzebujecie kogoś, kto ogarnia integracje i właścicielstwo po stronie biznesu.
Model rozliczenia bywa subskrypcyjny, co dla CFO oznacza koszt operacyjny zamiast dużego capeksu, a dla CISO przewidywalność. Sprzęt może być kupiony przez was albo przekazany w ramach dostawy, zależnie od dostawcy. Warto dopytać wprost, bo to istotnie zmienia rachunek TCO i to, kto bierze ryzyko sprzętowe.
Profil ryzyka
Średni, z innym rozkładem niż DIY. Ryzyko technologiczne i operacyjne spada (dostawca odpowiada za to, że produkt działa i się aktualizuje), ale pojawia się ryzyko zależności od dostawcy. Jeśli dostawca zniknie, podniesie ceny albo przestanie rozwijać produkt, macie problem, którego skala zależy od tego, jak głęboko produkt jest wpięty w wasze procesy.
To ryzyko da się kontraktowo ograniczyć: klauzule wyjścia, dostęp do danych w otwartym formacie, gwarancje ciągłości, escrow kodu w skrajnych przypadkach. CISO, który ocenia ten model, powinien czytać umowę pod kątem "co się stanie, gdy dostawca zawiedzie" równie uważnie jak pod kątem funkcji.
Kiedy ma sens
Productized appliance ma sens dla organizacji, która chce wartość z AI bez budowania kompetencji AI od zera, i która ceni przewidywalność oraz gotową dokumentację audytową bardziej niż pełną kontrolę nad każdą warstwą. To zwykle dobry wybór dla średnich i większych producentów (200 do 2000 FTE), gdzie IT istnieje i jest kompetentne, ale nie jest zespołem ML.
Model 3: Managed on-prem
Trzeci model to wariant, w którym sprzęt stoi u was (dane nie wychodzą, perymetr zachowany), ale całość jest zdalnie zarządzana przez dostawcę. To połączenie kontroli lokalizacji danych z modelem obsługi zbliżonym do usługi zarządzanej. Wy zapewniacie miejsce i łącze, dostawca odpowiada za to, że system działa, jest aktualny i utrzymany.
Profil kosztów
Najbardziej przewidywalny z trzech, ale niekoniecznie najniższy. Płacicie za to, że nie musicie mieć własnej kompetencji utrzymaniowej w ogóle. To koszt operacyjny, zwykle subskrypcyjny, obejmujący zarządzanie. Sprzęt, w zależności od dostawcy, bywa elementem usługi.
Z perspektywy obciążenia zespołu to model najlżejszy: wasz zespół nie utrzymuje ani platformy, ani modeli, ani pipeline'u. To istotne dla organizacji, które po prostu nie mają i nie chcą budować zdolności utrzymaniowej w tym obszarze.
Profil ryzyka
Tu pojawia się ciekawy paradoks regulacyjny. Z jednej strony dane nie opuszczają perymetru, co jest mocne pod NIS2 i RODO. Z drugiej, zdalne zarządzanie oznacza, że dostawca ma dostęp administracyjny do systemu stojącego w waszej serwerowni. To trzeba zmapować w analizie ryzyka: jak wygląda ten dostęp, jak jest logowany, jak segmentowany, co dostawca widzi a czego nie.
Dla audytu to nie jest dyskwalifikujące, wręcz przeciwnie, bywa czystsze niż DIY, bo dostawca zwykle przychodzi z gotowym modelem kontroli dostępu i logowania. Ale wymaga świadomej decyzji i udokumentowania, nie machnięcia ręką. Zależność od dostawcy jest tu najwyższa z trzech modeli, bo oddajecie nie tylko budowę, ale i bieżącą obsługę.
Kiedy ma sens
Managed on-prem ma sens dla organizacji, dla których lokalizacja danych jest twardym wymogiem (regulacyjnym lub politycznym), ale budowa i utrzymanie własnej kompetencji AI nie ma uzasadnienia biznesowego. To częsty profil średniego producenta będącego podmiotem kluczowym NIS2: musi mieć dane u siebie, ale nie chce i nie powinien zostać operatorem platformy AI.
Porównanie: koszt, ryzyko, obciążenie zespołu
Zestawienie skrótowe, do rozmowy wewnętrznej. Liczby konkretne zależą od skali, więc podaję profile, nie kwoty.
DIY na open-source. Koszt licencji niski, koszt ludzi wysoki, koszt sprzętu po waszej stronie. Ryzyko: wysokie organizacyjne (kluczowe osoby, audytowalność), niskie zależności od dostawcy. Obciążenie zespołu: najwyższe. Kontrola: pełna.
Productized appliance. Koszt oprogramowania średni do wysokiego, koszt ludzi niski, koszt sprzętu zależny od dostawcy. Ryzyko: średnie, głównie zależność od dostawcy (ograniczalna kontraktowo). Obciążenie zespołu: średnie do niskiego. Kontrola: częściowa, z gotową dokumentacją audytową.
Managed on-prem. Koszt operacyjny przewidywalny, koszt ludzi najniższy, sprzęt zwykle w usłudze. Ryzyko: najniższe operacyjne, najwyższa zależność od dostawcy plus kwestia dostępu zdalnego do zmapowania. Obciążenie zespołu: najniższe. Kontrola: nad danymi pełna, nad systemem ograniczona.
Wniosek, który warto wynieść: nie ma modelu "najlepszego". Jest model dopasowany do tego, ile kompetencji AI chcecie i możecie utrzymać oraz jak wyceniacie kontrolę względem przewidywalności.
Jak wybrać: cztery pytania
Zanim wejdziecie w RFP, odpowiedzcie sobie wewnętrznie na cztery pytania. One zwykle rozstrzygają wybór modelu szybciej niż dowolna prezentacja dostawcy.
- Czy AI jest dla nas kompetencją strategiczną, czy narzędziem? Jeśli strategiczną i mamy zespół, DIY wchodzi w grę. Jeśli narzędziem, odpada niemal zawsze.
- Czy mamy lub chcemy mieć zdolność utrzymaniową w tym obszarze? Jeśli nie, productized albo managed. Szczerość tutaj oszczędza rok bólu.
- Jak wyceniamy kontrolę względem przewidywalności? To pytanie o kulturę organizacji równie mocno jak o technologię.
- Co audytor zobaczy za 18 miesięcy? Wybierzcie model, dla którego odpowiedź na pytanie "skąd ta odpowiedź AI i kto miał dostęp" jest gotowa, a nie do dopisania w noc przed audytem.
// disclosure i biasesDisclosure i biases
Autor pracuje nad productized on-prem AI platform dla europejskich producentów. To oznacza realny bias w kierunku kategorii productized i managed względem DIY. Tam, gdzie ten bias mógłby zaważyć na wnioskach, starałem się zaznaczyć to wprost: DIY jest właściwym wyborem dla organizacji z istniejącą kompetencją ML i potrzebą pełnej kontroli, i w tych przypadkach moja preferencja kategorii jest po prostu nieadekwatna. Liczby kosztowe podaję jako profile, nie jako oferty, właśnie po to, żeby nie sprzedawać konkretnego modelu pod pozorem analizy.
// co tu nie pokrywamCo tu nie pokrywam
Świadomie pominąłem kilka rzeczy, żeby ten post pozostał o modelach wdrożenia, a nie o wszystkim naraz:
- Warianty hybrydowe i izolowana chmura publiczna. Inny profil ryzyka regulacyjnego, osobny temat.
- Konkretny dobór modelu językowego i benchmarki GPU. To osobna notatka o sizingu, gdzie liczby mają sens tylko z konkretną konfiguracją.
- Mapowanie na poszczególne artykuły NIS2 i AI Act. Dotykam regulacji ramowo, pełne mapowanie wymaga osobnego materiału w klastrze compliance.
- Federacja modeli między oddziałami i wielolokalizacyjność. Istotne dla dużych grup, poza zakresem tej analizy.
Buduje CortexMine, on-prem AI platform dla europejskich producentów objętych NIS2. Tam, gdzie ta stronniczość mogłaby zaważyć na wnioskach, oznacza to inline.
Chcesz przełożyć to na swój przypadek: architekturę, zgodność i koszt?
→ Umów 30 minBare-metal, colo czy appliance: gdzie postawić on-prem AI (CAPEX i OPEX)
Bare-metal we własnej serwerowni, colo z dedykowanym sprzętem, managed appliance dostarczany przez vendora. Trzy modele on-prem deploymentu AI w europejskiej produkcji 2026: liczby CAPEX i OPEX, profile ryzyka NIS2, kiedy który ma sens, i kiedy lepiej zrezygnować z on-prem w ogóle.
AI on-prem w europejskiej produkcji 2026: kompletny przewodnik architektoniczny
Architektura, GPU sizing, bezpieczeństwo, integracje, TCO, build vs buy. Praktyczny przewodnik wdrożenia AI on-prem dla CISO i CIO w europejskiej produkcji w 2026.