AI vendor lock-in: three layers and two contractual traps
Reading time: ~7 min · Cluster: Vendor evaluation · Level: CISO / CIO
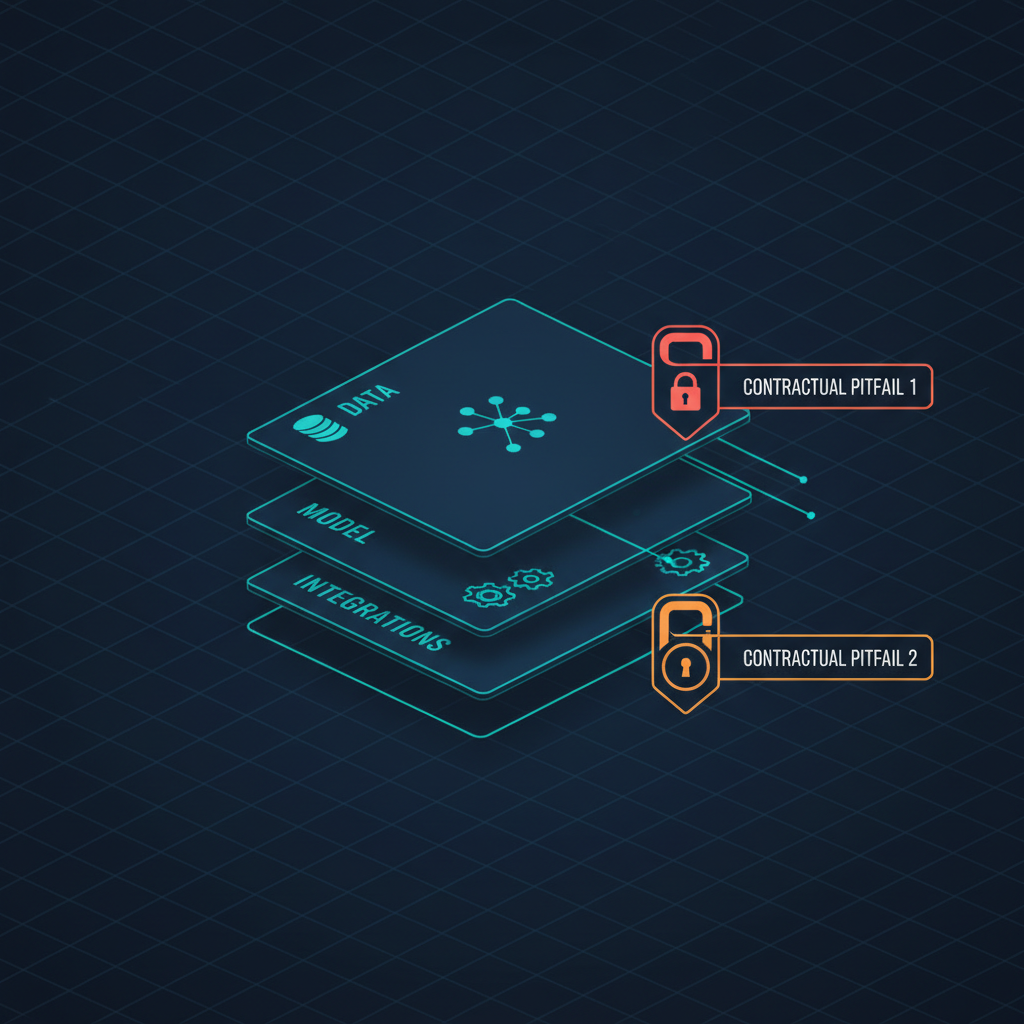
[IMAGE — in-body cover to generate: schematic, three stacked layers "data / model / integrations" with two warning markers at the contract. Not stock.]
Vendor lock-in in AI rarely looks like a single bad decision. More often it's the sum of a dozen reasonable steps: you picked a provider because it had the best model, bolted on an ERP integration because it was ready, trained your team on its interface. Each step made sense on its own. Together they produced a situation where switching providers means rewriting half the process.
For an entity in scope of the NIS2 Directive, this is not just a cost problem. The ability to terminate a provider relationship without losing operational capability is part of supply-chain security — and that falls under Article 21(1)(d). In other words: lock-in you can't describe and mitigate is also a compliance risk.
Below I break AI lock-in into three layers and show two traps that even experienced teams miss most often — because they sit not in the architecture, but in the contract.
Table of contents
- Why AI lock-in differs from SaaS lock-in
- Layer 1: data
- Layer 2: model
- Layer 3: integrations and workflow
- Contractual trap 1: portability and data egress
- Contractual trap 2: sub-processors and change-of-terms
- A short pre-MSA checklist
- What I don't cover here
- Disclosure and biases
Why AI lock-in differs from SaaS lock-in
In classic SaaS, lock-in is reasonably measurable: data lives in a database, export is a CSV or an API, migration cost can be estimated. AI adds three things SaaS doesn't have.
First, some of your "data" isn't input data at all but generated artifacts — embeddings, vector indexes, fine-tunes. Those artifacts are tied to a specific model and do not port 1:1. Second, system behaviour depends on a layer you usually don't control: the model, which the provider can version, deprecate, or swap out. Third, AI reaches deep into the workflow — it wires into ERP, MES, DMS, and identity — so the cost of leaving grows with every integration, often invisibly.
That's why it pays to assess lock-in layer by layer, rather than as a single "is it easy to switch providers" question.
Layer 1: data
This is the layer teams understand best — and still underestimate.
The real problem isn't the source documents (those usually live with you), but the derived artifacts: embeddings for the whole corpus, vector indexes, conversation logs, and feedback loops. If the provider computes embeddings with its own closed model, then at migration you don't export embeddings — you have to re-embed the entire corpus with a different model. For a knowledge base counted in hundreds of thousands of documents, that's a real cost in time and compute, not a formality.
Control questions for this layer:
- In what format can you export embeddings and the vector index — and are they usable outside the provider's stack?
- Who owns the conversation logs and feedback? Are they used as training data?
- Are there egress fees on the way out?
On-prem doesn't remove this layer automatically. Data can physically sit with you and still be trapped in a closed index format. Physical control is not the same as portability.
Layer 2: model
This is where lock-in is most insidious, because system behaviour is tuned to one specific model.
Prompts, guardrails, and RAG logic are tuned to a single model. Fine-tunes are bound to its weights and non-portable. And versioning sits with the provider — deprecation or a silent base-model update can change outputs and force a full re-validation of the solution. For an entity documenting its system under the EU AI Act, such a change isn't the provider's convenience; it's your re-validation cost.
On-prem mitigates this layer the most (you control whether and when you update the model), but it doesn't zero it out — a dependency on a specific inference stack and hardware-specific optimisations remains. The question isn't "do I have model lock-in," but "how deep is it, and who decides on a version change."
Layer 3: integrations and workflow
The deepest and least visible layer. You won't see it in the reference architecture — you'll see it only when you try to leave.
It's made of: connectors to ERP/MES/DMS, identity integration (SSO), data pipelines, a proprietary orchestration or agent framework, and — the thing most often overlooked — people trained on one specific interface. Each of these is small on its own. Together they create a switching cost that, after a year, can exceed all the other layers combined.
A practical defence: keep business logic (prompts, rules, mappings) in a layer you control, not inside the provider's proprietary orchestrator. The more of your logic that lives in a portable format, the shallower this layer of lock-in.
For clarity, the three layers in one view:
| Layer | What holds you | Does on-prem help? | First test |
|---|---|---|---|
| Data | Embeddings, indexes, logs as training data | Partly (format ≠ location) | Is the export usable outside the provider's stack? |
| Model | Fine-tunes, single-model tuning, versioning | Strongly (you control updates) | Who decides on a model version change? |
| Integrations | ERP/MES/SSO, orchestration, trained people | Weakly (this is your side) | How much of your logic lives outside the provider? |
Contractual trap 1: portability and data egress
Here begins the part that's easiest to miss, because it isn't technical.
You can have a perfect on-prem architecture and still be trapped — if the MSA is silent about exit. The classic set of gaps: no clause granting the right to export in an open format (and on a recurring basis, not only at termination), no SLA for the return and deletion of data after termination, unclear ownership of fine-tunes and embeddings, and auto-renewal coupled with price escalation.
What to have written down before you sign:
- A right to export data and derived artifacts in a documented, open format — available during the term, not only at the end.
- Unambiguous ownership of fine-tunes, embeddings, and logs.
- An SLA for the return and confirmed deletion of data after expiry (also relevant under GDPR).
- No automatic renewal without a notice window and without a cap on the increase.
For a NIS2 in-scope entity, this clause is not a "nice to have." The ability to end a provider relationship without losing operational capability is directly part of supply-chain security under Article 21.
Contractual trap 2: sub-processors and change-of-terms
The second trap concerns not what you sign today, but what the provider can change tomorrow — unilaterally.
Typical risks: the provider adds or changes a sub-processor, moves processing or inference to another jurisdiction, or swaps the base model — all without your consent and sometimes without notice. For an ordinary company that's an inconvenience. For a NIS2 in-scope entity it's a direct supply-chain risk (Article 21(1)(d)), and on a model change — also a re-validation cost under the EU AI Act.
What to look for in the contract:
- A right to prior notice and objection to a change of sub-processor or processing location.
- A commitment to notify you of a base-model change/update in advance.
- A ban on moving processing outside the agreed region without your consent.
Lacking these clauses means your compliance risk profile is in the provider's hands — and can change with a terms-update email.
A short pre-MSA checklist
Six questions worth asking before you sign anything:
- In what format do I export data and derived artifacts — and are they usable outside the provider's stack?
- Who owns the fine-tunes, embeddings, and logs?
- Who decides on a model version change, and when?
- How much of my business logic lives outside the provider's orchestrator?
- What notice/objection rights do I have over a sub-processor or jurisdiction change?
- What's the SLA for the return and deletion of data after the contract ends?
If the answer to three of these is "I don't know," you have lock-in — you just haven't priced it yet.
What I don't cover here
I deliberately don't go into: a full vendor scoring framework (a separate, larger piece), the details of conformity assessment under the EU AI Act, sector-specific regulation (energy, healthcare, finance), or price-negotiation tactics. This is a note about recognising lock-in, not a complete guide to vendor evaluation.
// disclosure & biasesDisclosure and biases
We write from the perspective of a team that builds on-prem AI systems, not one selling a specific product in this article. That may tilt our assessment toward solutions that give you control over the model and data layers. Where that bias could shape the conclusions, we try to flag it inline.
Next step
This site doesn't sell — it takes notes. In the meantime, follow us on LinkedIn: linkedin.com/in/fryderykpryjma
Building CortexMine, an on-prem AI platform for European manufacturers under NIS2. Where this bias could affect conclusions, it is flagged inline.
Want to apply this to your case: architecture, compliance, and cost?
→ Book 30 minOn-prem AI vs cloud TCO: how to calculate over three years
TCO is not decided by the GPU price tag, but by utilization and horizon. How to model on-prem AI vs cloud over three years: three different cost models, a full CAPEX and OPEX line-item list, the break-even point and an honest look at when cloud wins.
Vendor security review for AI: 12 questions before signing an MSA
Twelve questions to put to an AI vendor before you sign an MSA, in four blocks: data location, sub-processors, operational security, and exit terms.