On-prem RAG: architecture, chunking, retrieval and what actually drives quality
How to build RAG outside the public cloud: the pipeline layers, the most common retrieval failures, the data boundary inside the prompt, and the questions an auditor will ask. A technical note for architects and CISOs.
Reading time: ~7 min
Who this is for: the IT architect, security architect, CISO, or infrastructure lead weighing RAG (retrieval-augmented generation) on their own infrastructure, who wants to understand where the architecture actually hurts before signing off on a project.
Table of contents
- Why run RAG outside the public cloud at all
- Anatomy of a RAG pipeline (seven layers)
- Retrieval: where it breaks most often
- What actually lands in the prompt (and why it is a governance problem)
- Security boundaries: isolation, logging, access control
- Three architectural decisions that are hard to reverse
- Disclosure and biases
- What this note does not cover
- Related
1. Why run RAG outside the public cloud at all
RAG is a pattern where a language model does not answer from its own knowledge alone, but receives document fragments pulled from the organization's own store as context. That lets it answer questions about data that was never in training: service documentation, contracts, safety instructions, ticket history.
The reason an organization runs RAG on its own infrastructure is usually a single one: the data feeding retrieval must not leave the environment. Technical documentation, employee personal data, contract details, process know-how. Once that content is indexed and sent to a public API as prompt context, the organization is exporting it to an external processor, with every consequence that carries through the supply chain.
This is not a post about whether to keep RAG local. That depends on the risk profile and there is no single answer. It is a post about how such a pipeline looks technically and where teams most often lose time or security.
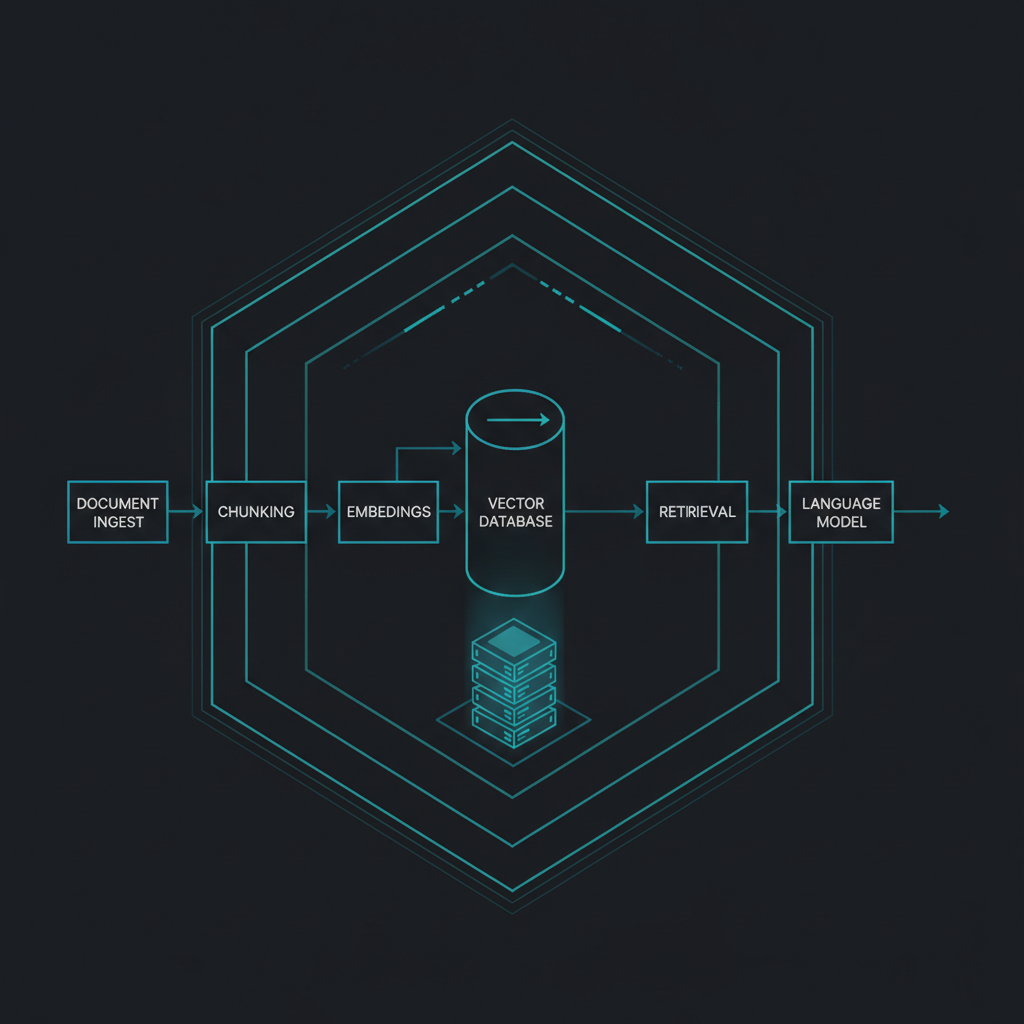
2. Anatomy of a RAG pipeline (seven layers)
A working RAG system is not "a vector database plus a model." It is a chain in which every link has its own failure modes.
Layer 1, ingest and parsing. Documents arrive in mixed formats: PDF (often scans), DOCX, intranet pages, exports from ERP/MES systems. The parser turns them into clean text. This is where the most quality is lost: tables collapse into strings of numbers, headings blur into body text, scans without OCR return nothing.
Layer 2, chunking. Text is cut into fragments. Chunks that are too large dilute relevance; chunks that are too small lose context (the sentence "does not apply to model X" severed from what it does not apply to is worse than no sentence at all).
Layer 3, embeddings. Each chunk gets a vector from an embedding model. In an on-prem setup this model also runs locally, and its quality for Polish is often markedly worse than for English, which feeds back into the whole retrieval step.
Layer 4, vector database. Vectors land in an index (e.g. pgvector, Qdrant, Milvus). This is where you decide on the similarity metric, the index type, and metadata filtering.
Layer 5, retrieval. For a user query the system fetches the closest chunks. This is the heart of the pattern and also the place where "works in the demo" most often diverges from "works in production."
Layer 6, generation. The retrieved fragments go into the prompt alongside the question, and the language model formulates an answer. This is where it is settled how much of the supplied context the model actually uses, and how much it ignores or distorts.
Layer 7, observability and feedback. Query logging, relevance scoring, an improvement loop. The most frequently skipped layer, and without it you can neither improve the system nor document how it behaves for an auditor.
3. Retrieval: where it breaks most often
Most disappointment with RAG is not the language model's fault, it is retrieval. Four recurring patterns:
Semantic relevance ≠ factual relevance. Vector search finds fragments that are topically similar, not necessarily ones that answer the question. A query about the torque value for a specific bolt pulls five paragraphs about bolts in general, but not necessarily the one with the value table.
No hybrid. Pure vector search misses queries where an exact token matters: part number, error code, standard reference. Full-text search (e.g. BM25) catches those instantly. Production systems almost always need a hybrid of vector plus keyword, not one of the two.
No permission filtering at the retrieval layer. If access control is wired in only at the application layer while retrieval scans the whole index, the model can receive a fragment in context that the user should not see, and summarize it in the answer. The permission-metadata filter has to run inside the query to the database, not after it.
No evaluation. Without a set of test questions with expected sources, the team does not know whether a change to chunking or to the embedding model improved the system or broke it. "Seems better" is not a metric.
4. What actually lands in the prompt (and why it is a governance problem)
A key observation that is easy to miss during design: at generation time, raw document fragments land in the model's prompt, often carrying data the user asking the question has no right to see in full, or data that is sensitive in itself.
That raises concrete questions worth settling at the architecture stage, not after an incident:
- Are the fragments entering the context logged? If so, where and for how long? A RAG prompt log is often the most sensitive data store in the whole system, because it holds out-of-context fragments from many documents at once.
- Do we mask personal data before indexing, or do we trust that it will never flow into the prompt? The first is costly; the second is an assumption an auditor will challenge.
- Who has access to the vector database? Vectors are not "encrypted," because with the right model a significant share of the source content can be reconstructed from them. Access to the index is roughly access to the documents.
In a regulatory context these questions are not theoretical. The line between "the data is with us" and "the data is in the logs of a system five people can access with no clear justification" is exactly the level of detail at which supply-chain risk assessment is decided.
5. Security boundaries: isolation, logging, access control
Three areas that an on-prem RAG has to be designed for deliberately, because no one will do it for the organization:
Network segmentation. The RAG pipeline touches data sources (ERP, file shares, intranet), the vector database, and the model server. Each of those connections is a potential leak path. A minimal rule set: the model server initiates no outbound traffic, the vector database is reachable only from the application layer, ingest runs in a separate segment.
Audit logging at the retrieval layer. Not just "user X asked a question," but "query X pulled documents A, B, C and returned answer Y." Without that you cannot reconstruct where a wrong or sensitive answer came from, and that is the first question after an incident.
Access control propagated into retrieval. Repeating from section 3, because it is the most common design error: permissions have to filter what retrieval sees at all, not only what the application shows at the end.
6. Three architectural decisions that are hard to reverse
The embedding model. Changing the embedding model means recomputing the entire index from scratch. On large corpora that is hours to days of GPU work and a window in which the system runs on stale vectors. The choice is worth testing on a representative subset before production indexing, with particular attention to quality for Polish.
The chunking strategy. Tied to the above, because changing how text is cut also requires reindexing. It is worth investing in structure-aware chunking (sections, tables, headings) rather than naive cuts every N characters.
The logging boundary. The decision about what from prompts and context gets stored is hard to undo retroactively: data that landed in logs over six months is already there. Better to design restrictively and loosen later than the other way around.
The architecture cluster naturally meets the build-vs-buy decision here: which layers you build and maintain in-house, and which you close off with a ready component. That is the subject of neighboring notes in vendor evaluation, which I will return to separately.
// disclosure & biases7. Disclosure and biases
The author works on CortexMine, a productized on-prem AI platform for European manufacturers. The analysis in this post may be biased toward the productized-vs-DIY category, in particular where I describe the cost of maintaining the observability and logging layers as high. A team with strong in-house MLOps competence may rate those costs lower than this text suggests. Where possible, I have tried to describe the layers neutrally, regardless of who supplies them.
8. What this note does not cover
- Concrete embedding-model benchmarks for Polish, because that is material for a separate note with numbers, not a paragraph.
- Fine-tuning vs RAG, i.e. when it is worth fine-tuning a model instead of building retrieval; a separate trade-off.
- Agentic architectures (multi-step retrieval, tool use), because that is a layer above classic RAG.
- Detailed mapping onto NIS2 articles. I signal the regulatory context, but the full mapping lives in the NIS2 cluster.
- Hardware sizing for inference, covered separately in GPU sizing for Llama 3.1 70B.
9. Related
Building CortexMine, an on-prem AI platform for European manufacturers under NIS2. Where this bias could affect conclusions, it is flagged inline.
GPU sizing for Llama 3.1 70B inference: numbers from benchmarks
How many GPUs does it really take to run Llama 3.1 70B in-house? Concrete configs (A100, H100, H200), the impact of quantization (FP16 → FP8 → INT4), tokens/s, TTFT, and cost per 1M tokens. No marketing — numbers from vLLM and TensorRT-LLM benchmarks.